Concepto básico de Análisis de código máquina
Este capítulo ofrece una descripción general de los conceptos básicos de Análisis de código máquina integrados en EcoStruxure Machine Expert.
Componentes de software de Análisis de código máquina
El diagrama ofrece una descripción general de los componentes de software de alto nivel de Análisis de código máquina:
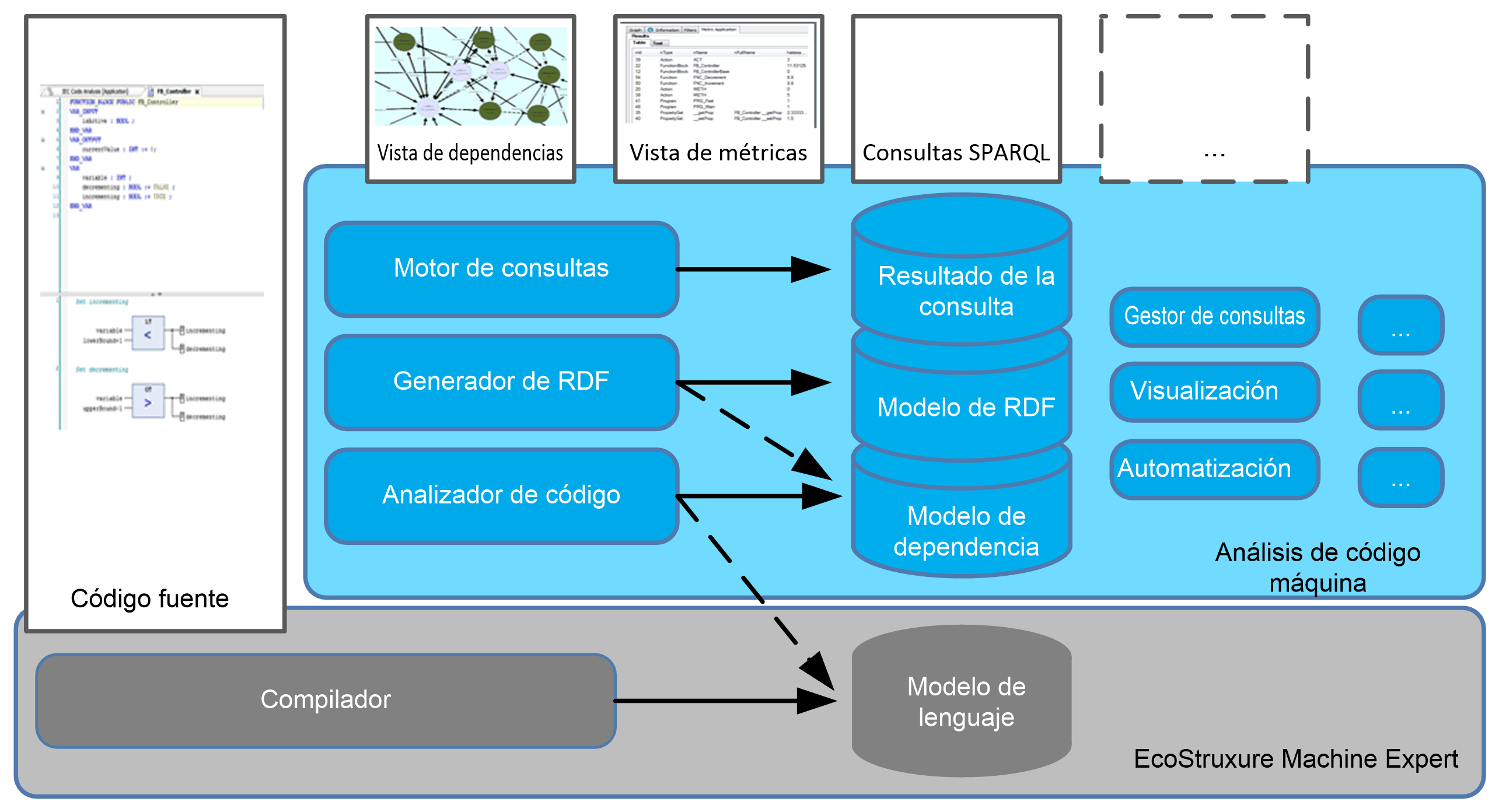
Los componentes se pueden clasificar en tres tipos distintos:
oComponentes de UI que muestran datos:
oEditores para escribir el código fuente.
oEditores para visualizar los resultados como métricas o convenciones, o una representación gráfica de la estructura del código fuente.
oModelos de datos como entrada o salida de otros componentes:
oModelo de lenguaje
oModelo de dependencia
oModelo RDF
oResultados de la consulta
oComponentes que transforman datos:
oEl compilador de código fuente (con modelo de lenguaje como salida) procesa el código fuente para comprobar la sintaxis y crear el modelo de lenguaje para generar el código ejecutable de los controladores.
oEl analizador de código fuente (con modelo de dependencia como salida) analiza el modelo de lenguaje y lo transforma en un modelo de dependencia (y lo mantiene actualizado).
oEl generador de modelo RDF (con modelo RDF como salida) transforma el modelo de dependencia en un modelo RDF para generar la conexión con las tecnologías web semánticas.
oEl motor de ejecución de consultas (con los resultados de la consulta como salida) ejecuta consultas SPARQL en el modelo RDF para obtener resultados de la consulta.
Concepto de datos de análisis (modelo de dependencia)
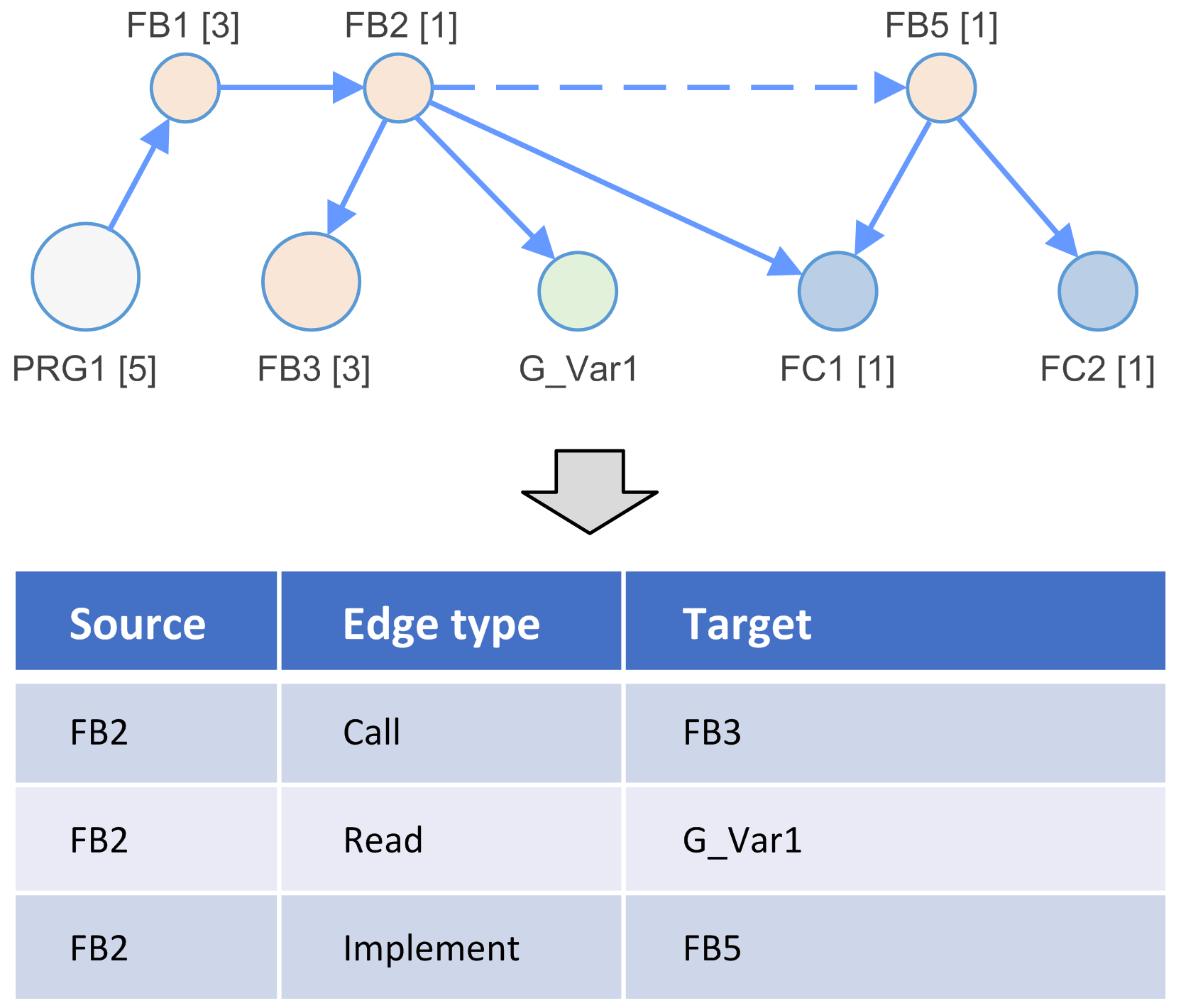
Se analiza la aplicación y se crea un modelo de dependencia.
El modelo de dependencia es una lista de nodos conectados mediante flancos.
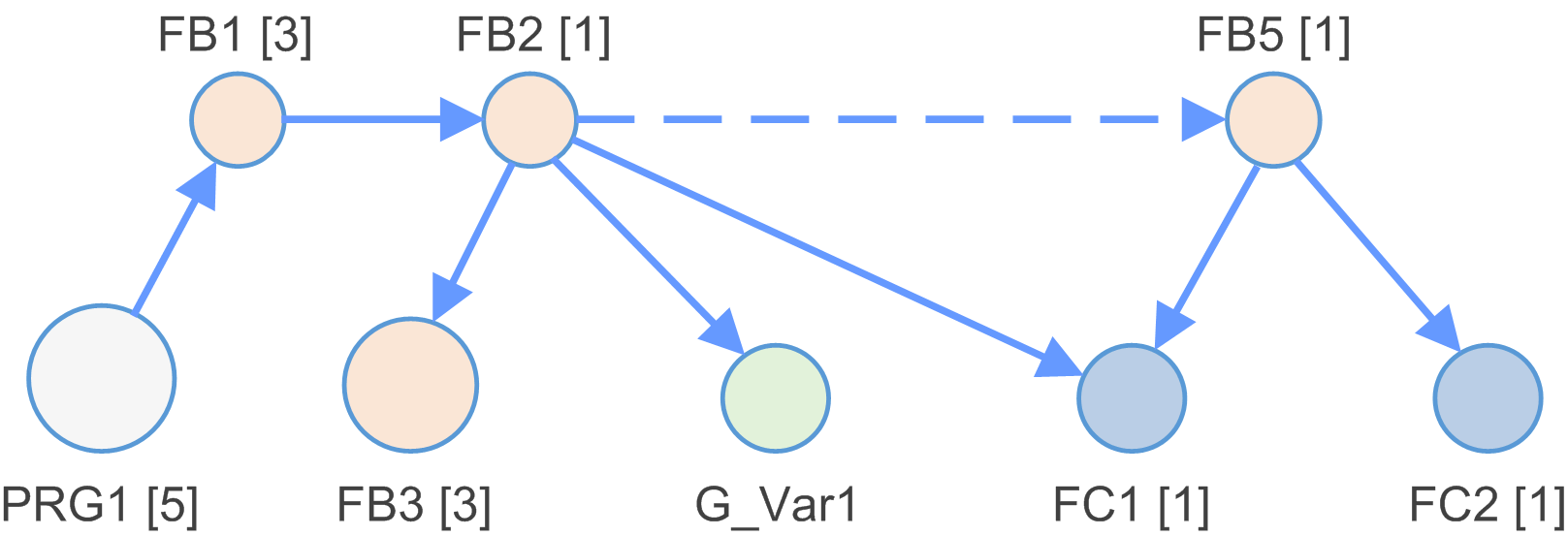
Ejemplos de tipos de nodos:
|
Tipo de nodo |
Descripción |
|---|---|
|
Bloque de funciones |
Bloque de funciones (FB) dentro del modelo de dependencia. Se crea para cada bloque de funciones añadido al proyecto de EcoStruxure Machine Expert. |
|
Programa |
Programa (PRG) dentro del modelo de dependencia. Se crea para cada programa añadido al proyecto de EcoStruxure Machine Expert. |
|
Función |
Función (FC) dentro del modelo de dependencia. Se crea para cada función añadida al proyecto de EcoStruxure Machine Expert. |
|
... |
... |
Ejemplos de tipos de flancos:
|
Tipo de flanco |
Descripción |
|---|---|
|
Lectura |
Operación de lectura del código como origen a un nodo de variable como destino. |
|
Escritura |
Operación de escritura del código como origen a un nodo de variable como destino. |
|
Llamada |
Llamada de un bloque de funciones, método, acción, programa, etc., del código como origen a un nodo de destino. |
|
Extensión |
Extensión de un tipo base. Por ejemplo, extensión de FB realizada por otro bloque de funciones. |
|
... |
... |
Uno de los componentes más importantes del análisis de código es el analizador de código fuente que transforma el modelo de lenguaje en un modelo de dependencia (los datos de análisis).
Este analizador de código fuente se basa en un concepto llamado fases de análisis. Se utiliza para optimizar la facilidad de uso y el rendimiento (desde el punto de vista de la memoria y la CPU).
Ejemplo:
oObtener las dependencias de extensión e implementación es una operación rápida de análisis de código y requiere menos tiempo que las dependencias de llamada, lectura o escritura.
oPara obtener la lista de bloques de funciones y las dependencias de extensión e implementación, es suficiente con interrumpir el análisis en un momento específico de profundidad.
oSi se necesitan más detalles, debe aumentarse la profundidad del análisis en elementos concretos (por ejemplo, para visualizar algunos bloques de funciones en la vista de dependencias) o, quizá, para los objetos del proyecto (por ejemplo, para obtener resultados de métricas).
Hay cinco fases de análisis disponibles:
oFase 1: Crear nodos principales (por ejemplo, bloques de funciones).
oFase 2: Vincular nodos principales mediante flancos.
oFase 3: Crear nodos secundarios (por ejemplo, variables).
oFase 4: Vincular nodos secundarios mediante flancos.
oFase 5: Calcular métricas.
Fases de análisis relevantes para el usuario:
Hay tres enfoques relevantes:
oProfundidad de análisis mínima (fases 1 y 2): el contenido visible en el proyecto y los navegadores de EcoStruxure Machine Expert.
oFB, PRG, FC, DUT, etc.
oPropiedades y sus métodos de obtención/configuración
oMétodos
oAcciones
oInformación estructural (carpetas, etc.)
oReferencias de bibliotecas
Esta profundidad de análisis es la que menos tiempo requiere.
oProfundidad de análisis intermedia (fases 3 y 4): siguiente nivel de información del código fuente.
Por ejemplo:
oVariables
oLectura de dependencias de variables
oEscritura de dependencias de variables
oLlamada de métodos, funciones, bloques de funciones, programas, etc.
Esta profundidad de análisis requiere mucho tiempo.
oProfundidad de análisis máxima (fase 5): información métrica basada en la implementación (el código fuente).
Por ejemplo:
oComplejidad Halstead
oLíneas de código (LOC)
o...
Esta profundidad de análisis es la que más tiempo requiere (solo para métricas o convenciones).
La función de análisis de código abierto y flexible se basa en tecnologías web semánticas. Algunas de estas tecnologías son:
oResource Description Framework (RDF): modelo RDF
Consulte https://en.wikipedia.org/wiki/Resource_Description_Framework.
oBase de datos RDF (base de datos web semántica): un Triple Storage RDF
Consulte https://en.wikipedia.org/wiki/Triplestore
oProtocolo SPARQL y lenguaje de consultas RDF: SPARQL
Consulte https://en.wikipedia.org/wiki/SPARQL.
Modelo de dependencia para la sincronización de modelos RDF
El modelo de dependencia es el resultado de una ejecución de análisis de código.
Para vincularse a una función de análisis de código abierto y flexible con compatibilidad con lenguajes de consultas, el modelo de dependencia se sincroniza con un modelo RDF.
Para poder analizar proyectos grandes, el modelo RDF se mantiene en un proceso independiente llamado Triple Storage RDF.
De forma predeterminada, se utiliza Triple Storage RDF. Si es necesario, puede configurar este comportamiento en el Gestor de análisis de código.
Resource Description Framework (RDF) es un modelo de datos para describir recursos y las relaciones que se establecen entre ellos.
Ejemplo:
|
:(Sujeto) |
:(Predicado) |
:(Objeto) |
|---|---|---|
|
:Car |
:Weights |
:1000 kg |
|
:Car |
:ConsistsOf |
:Wheels |
|
:Car |
:ConsistsOf |
:Engine |
SPARQL es el acrónimo de Sparql Protocol and RDF Query Language (Protocolo Sparql y lenguaje de consultas RDF). La especificación SPARQL (https://www.w3.org/TR/sparql11-overview/) ofrece lenguajes y protocolos para realizar consultas y manipulaciones en grafos RDF, de forma similar a las consultas SQL.
Ejemplo de una consulta SPARQL simple para obtener los ID de nodos y los nombres de los bloques de funciones de un modelo RDF:
SELECT ?NodeId ?Name
WHERE {
# Select all FunctionBlocks and their names
?NodeId a :FunctionBlock ;
:Name ?Name .
}