Concepts de base de Analyse du code machine
Ce chapitre présente les concepts de base du composant Analyse du code machine intégré dans EcoStruxure Machine Expert.
Composants logiciels de Analyse du code machine
Le schéma suivant propose une vue d'ensemble des principaux composants logiciels de Analyse du code machine :
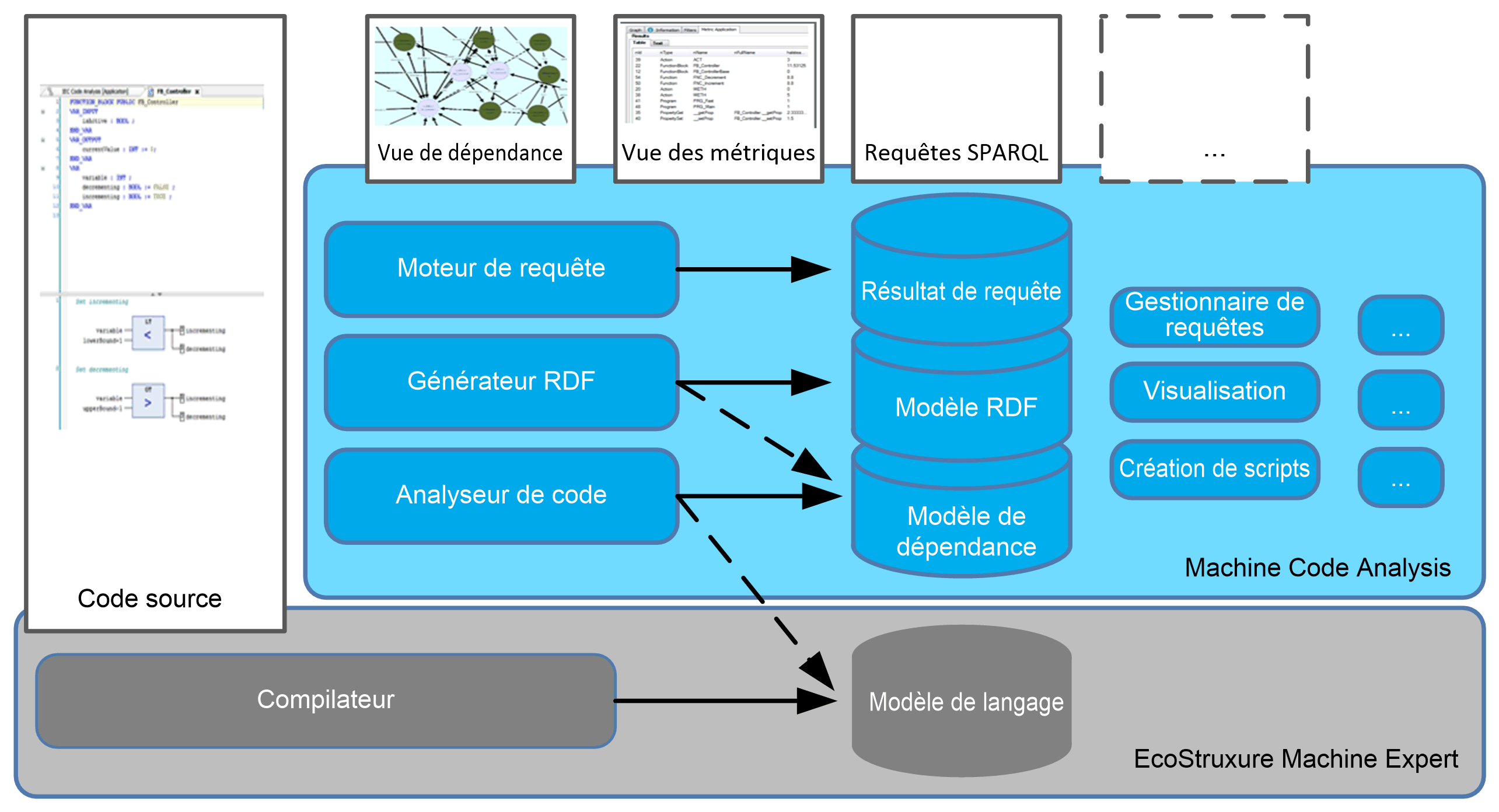
Ces composants peuvent être classés dans trois catégories :
oLes composants de l'interface utilisateur qui affichent des données :
oÉditeurs permettant d'écrire du code source
oÉditeurs permettant de visualiser les résultats concernant les métriques ou les conventions, ou la structure du code source sous forme graphique
oLes modèles de données utilisés comme entrée ou sortie pour d'autres composants :
oModèle de langage
oModèle de dépendance
oModèle RDF
oRésultats de requête
oLes composants qui transforment des données :
oLe compilateur de code source (avec modèle de langage en sortie) vérifie la syntaxe du code source et crée le modèle de langage qui permet de générer le code exécuté sur des contrôleurs.
oL'analyseur de code source (avec modèle de dépendance en sortie) analyse le modèle de langage, le transforme en modèle de dépendance et met à jour le modèle de dépendance.
oLe générateur de modèles RDF (avec modèle RDF en sortie) transforme le modèle de dépendance en modèle RDF pour faire le lien avec les technologies de Web sémantique.
oLe moteur d'exécution de requêtes (avec résultats de requête en sortie) exécute des requêtes SPARQL sur le modèle RDF afin d'obtenir les résultats correspondants.
Données d'analyse (modèle de dépendance)
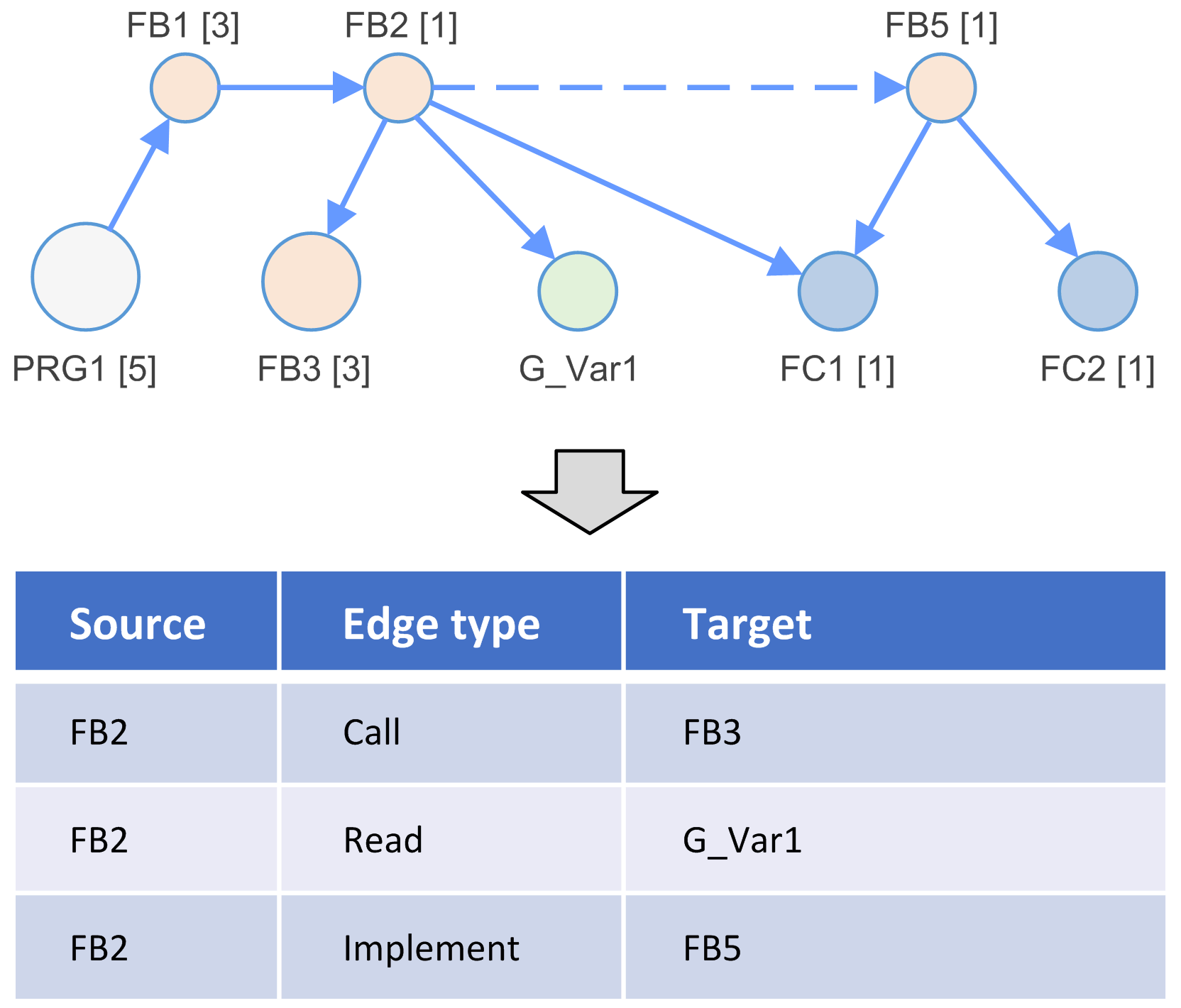
L'application est analysée et un modèle de dépendance est généré.
Le modèle de dépendance est constitué de nœuds connectés via des fronts.
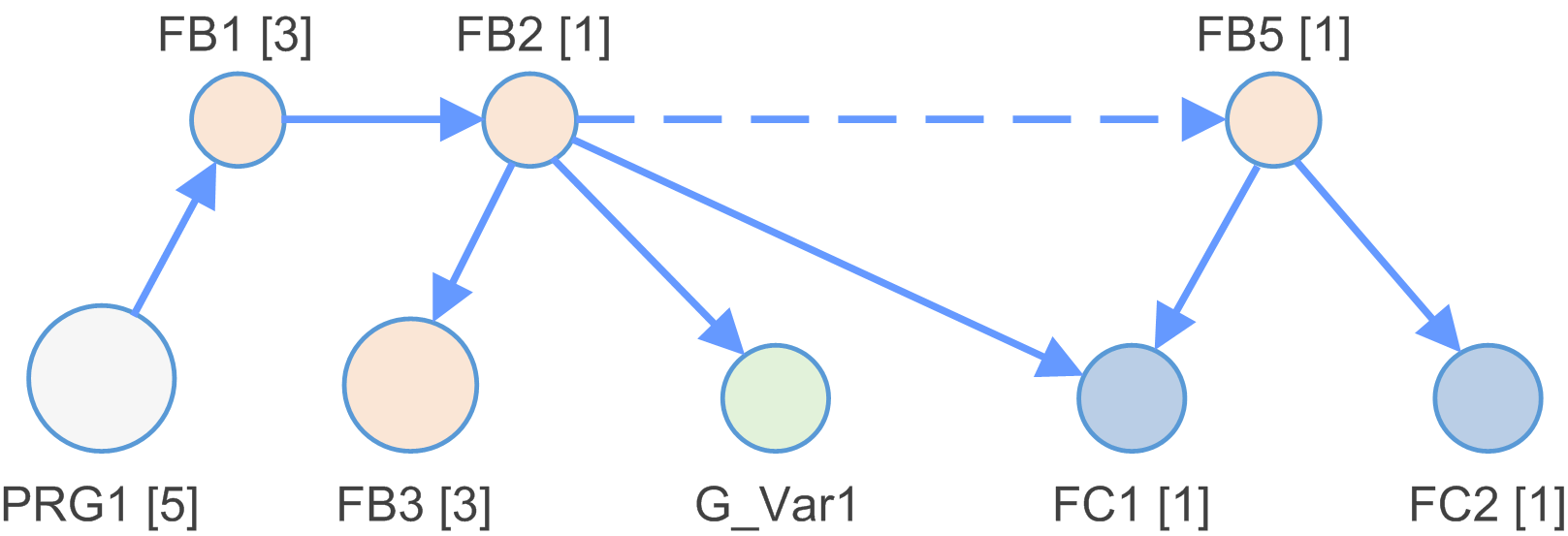
Exemples de types de nœuds :
|
Type de nœud |
Description |
|---|---|
|
Bloc fonction |
Bloc fonction (FB) dans le modèle de dépendance. Créé pour chaque bloc fonction ajouté au projet EcoStruxure Machine Expert. |
|
Programme |
Programme (PRG) dans le modèle de dépendance. Créé pour chaque programme ajouté au projet EcoStruxure Machine Expert. |
|
Fonction |
Fonction (FC) dans le modèle de dépendance. Créé pour chaque fonction ajoutée au projet EcoStruxure Machine Expert. |
|
... |
... |
Exemples de types de fronts :
|
Type de front |
Description |
|---|---|
|
Lecture |
Opération de lecture depuis le code (source) vers un nœud de variable (cible). |
|
Écriture |
Opération d'écriture depuis le code (source) vers un nœud de variable (cible). |
|
Appel |
Appel d'un élément (bloc fonction, méthode, action, programme, etc.) depuis le code (source) vers un nœud cible. |
|
Extension |
Extension d'un type de base. Exemple : extension d'un bloc fonction par un autre bloc. |
|
... |
... |
L'analyseur de code source, un des principaux composants de l'analyse de code, transforme le modèle de langage en modèle de dépendance (les données d'analyse).
Cet analyseur s'appuie sur le concept des phases d'analyse, qui permet de simplifier le processus et d'optimiser les performances (sur le plan de la mémoire et du processeur).
Exemple :
oL'analyse de code permettant d'obtenir les dépendances d'extension et d'implémentation est plus rapide comparé à celle renvoyant les dépendances d'appel, de lecture ou d'écriture.
oPour obtenir la liste des blocs fonction et des dépendances d'extension et d'implémentation, il suffit d'interrompre l'analyse à un niveau donné.
oSi vous avez besoin de plus de détails, augmentez la profondeur de l'analyse pour les éléments souhaités (pour visualiser des blocs fonction spécifiques dans la vue de dépendance, par exemple) ou pour les objets du projet (pour obtenir les résultats sur les métriques, par exemple).
Cinq phases d'analyse sont disponibles :
oPhase 1 : création des nœuds principaux (comme les blocs fonction)
oPhase 2 : liaison des nœuds principaux via des fronts
oPhase 3 : création des sous-nœuds (comme les variables)
oPhase 4 : liaison des sous-nœuds via des fronts
oPhase 5 : calcul des métriques
Phases d'analyse pertinentes pour l'utilisateur :
Les trois approches suivantes sont pertinentes :
oProfondeur d'analyse minimale (phases 1+2) : contenu visible dans le projet et les navigateurs d'EcoStruxure Machine Expert
oBlocs fonction, programmes, fonctions, DUT, etc.
oPropriétés et méthodes Get/Set associées
oMéthodes
oActions
oInformations structurelles (dossier, etc.)
oRéférences de bibliothèques
Avec cette profondeur, l'analyse prend le moins de temps.
oProfondeur d'analyse intermédiaire (phases 3+4) : niveau d'informations inférieur dans le code source
Par exemple :
oVariables
oLecture des dépendances de variable
oÉcriture des dépendances de variable
oAppel des méthodes, fonctions, blocs fonction, programmes, etc.
Avec cette profondeur, l'analyse prend beaucoup de temps.
oProfondeur d'analyse maximale (phase 5) : informations concernant les métriques basées sur l'implémentation (le code source)
Par exemple :
oHalstead Complexity
oLines Of Code (LOC)
o...
Avec cette profondeur, l'analyse prend le plus de temps. Réservé aux métriques ou aux conventions.
Technologies de Web sémantique
Ouverte et flexible, la fonction d'analyse de code s'appuie sur plusieurs technologies de Web sémantique, notamment :
oStructure Resource Description Framework (RDF) - Modèle RDF
Consultez la page https://en.wikipedia.org/wiki/Resource_Description_Framework.
oBase de données RDF (base de données de Web sémantique) - espace Triple Storage RDF
Consultez la page https://en.wikipedia.org/wiki/Triplestore.
oProtocole SPARQL et langage de requête RDF - SPARQL
Consultez la page https://en.wikipedia.org/wiki/SPARQL.
Synchronisation entre le modèle de dépendance et le modèle RDF
Le modèle de dépendance est généré suite à une opération d'analyse de code.
Il est synchronisé avec un modèle RDF pour faire le lien avec une fonction d'analyse de code ouverte et flexible qui prend en charge le langage de requête.
Pour permettre l'analyse de projets volumineux, le modèle RDF appartient à un processus séparé appelé Triple Storage RDF.
Le Triple Storage RDF est utilisé par défaut. Au besoin, il est possible de configurer son comportement à l'aide du Gestionnaire d'analyse de code.
La structure Resource Description Framework (RDF) désigne un modèle de données décrivant des ressources ainsi que les relations qui les lient.
Exemple :
|
:(Sujet) |
:(Prédicat) |
:(Objet) |
|---|---|---|
|
:Car |
:Weights |
:1000 kg |
|
:Car |
:ConsistsOf |
:Wheels |
|
:Car |
:ConsistsOf |
:Engine |
SPARQL est l'acronyme de « Sparql Protocol and RDF Query Language ». La spécification SPARQL (https://www.w3.org/TR/sparql11-overview/) définit les langages et protocoles qui permettent d'interroger et de manipuler des graphes RDF (à l'instar des requêtes SQL).
Exemple de requête SPARQL simple permettant d'obtenir l'ID de nœud et le nom des blocs fonction d'un modèle RDF :
SELECT ?NodeId ?Name
WHERE {
# Select all FunctionBlocks and their names
?NodeId a :FunctionBlock ;
:Name ?Name .
}