Konzept von Codeanalyse
Überblick
Dieses Kapitel bietet einen Überblick über die Konzepte der in EcoStruxure Machine Expert integrierten Komponente Codeanalyse.
Codeanalyse - Softwarekomponenten
Die nachstehende Abbildung bietet einen Überblick über die Softwarekomponenten auf oberster Ebene von Codeanalyse:
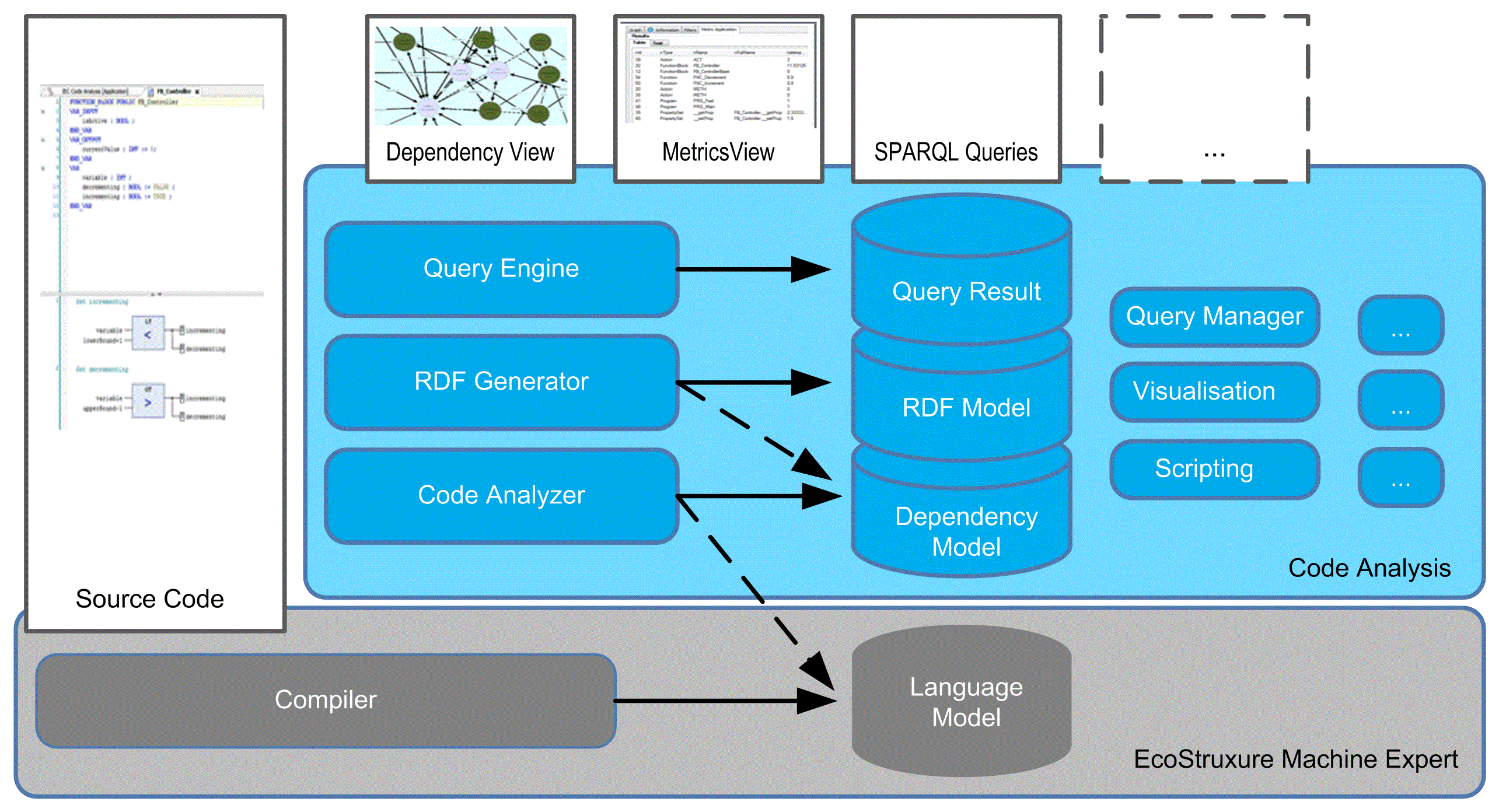
Die Komponenten lassen sich in 3 verschiedene Typen untergliedern:
-
UI-Komponenten zur Datenanzeige:
-
Editoren für das Schreiben des Quellcodes
-
Editoren für die Visualisierung der Ergebnisse wie Metriken oder Konventionen oder für eine grafische Darstellung der Struktur des Quellcodes
-
-
Datenmodelle als Ein- oder Ausgabe für andere Komponenten:
-
Sprachmodell
-
Abhängigkeitsmodell
-
RDF-Modell (Resource Description Framework)
-
Abfrageergebnisse
-
-
Komponenten zur Datentransformation:
-
Der Quellcode-Compiler (mit Sprachmodell als Ausgang) verarbeitet den Quellcode zur Überprüfung der Syntax und zur Erstellung des Sprachmodells, um den auf Steuerungen ausführbaren exe-Code zu erzeugen.
-
Der Quellcode-Analyzer (mit Abhängigkeitsmodell als Ausgang) analysiert das Sprachmodell und wandelt es in ein Abhängigkeitsmodell um (das er auf dem jeweils neuesten Stand hält).
-
Der RDF-Modellgenerator (mit RDF-Modell als Ausgabe) wandelt das Abhängigkeitsmodell in ein RDF-Modell um, um eine Brücke zu den semantischen Webtechnologien herzustellen.
-
Die Abfrageausführungs-Engine (mit Abfrageergebnissen als Ausgabe) führt SPARQL-Abfragen mit dem RDF-Modell aus, um entsprechende Abfrageergebnisse zu erhalten.
-
Konzept der Analysedaten (Abhängigkeitsmodell)
Die Anwendung wird analysiert und ein Abhängigkeitsmodell erstellt.
Bei einem Abhängigkeitsmodell handelt es sich um eine Liste mit Knoten, die über Kanten miteinander verbunden sind.
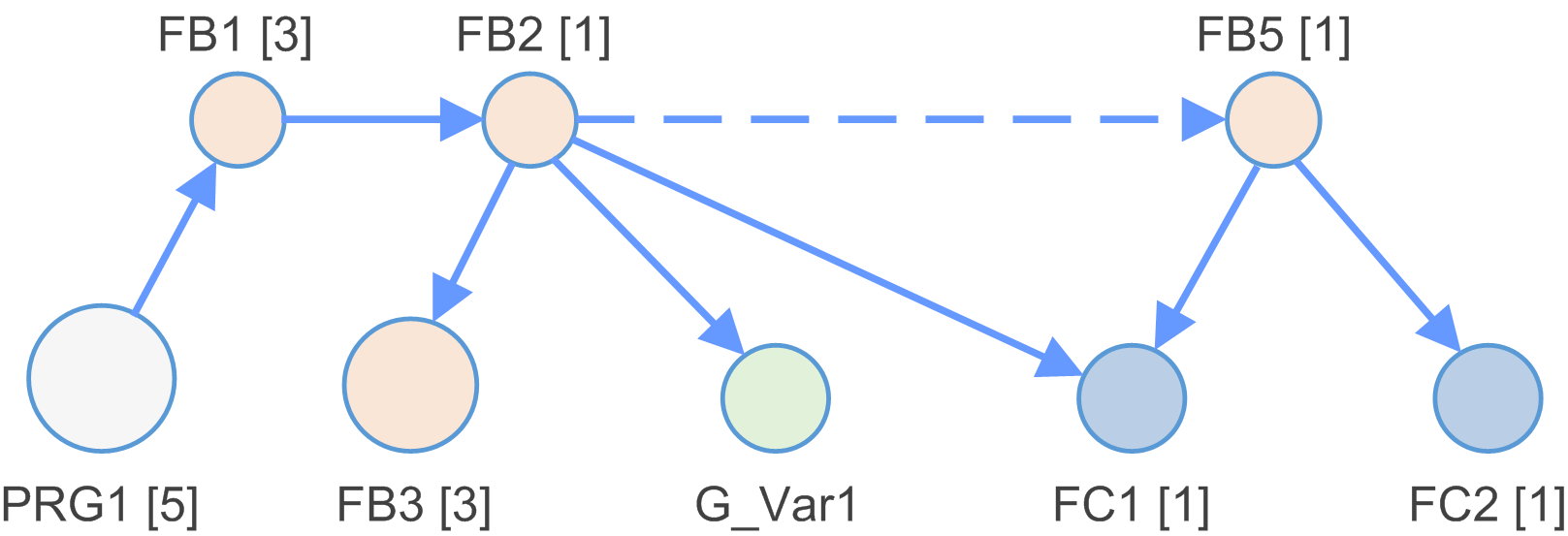
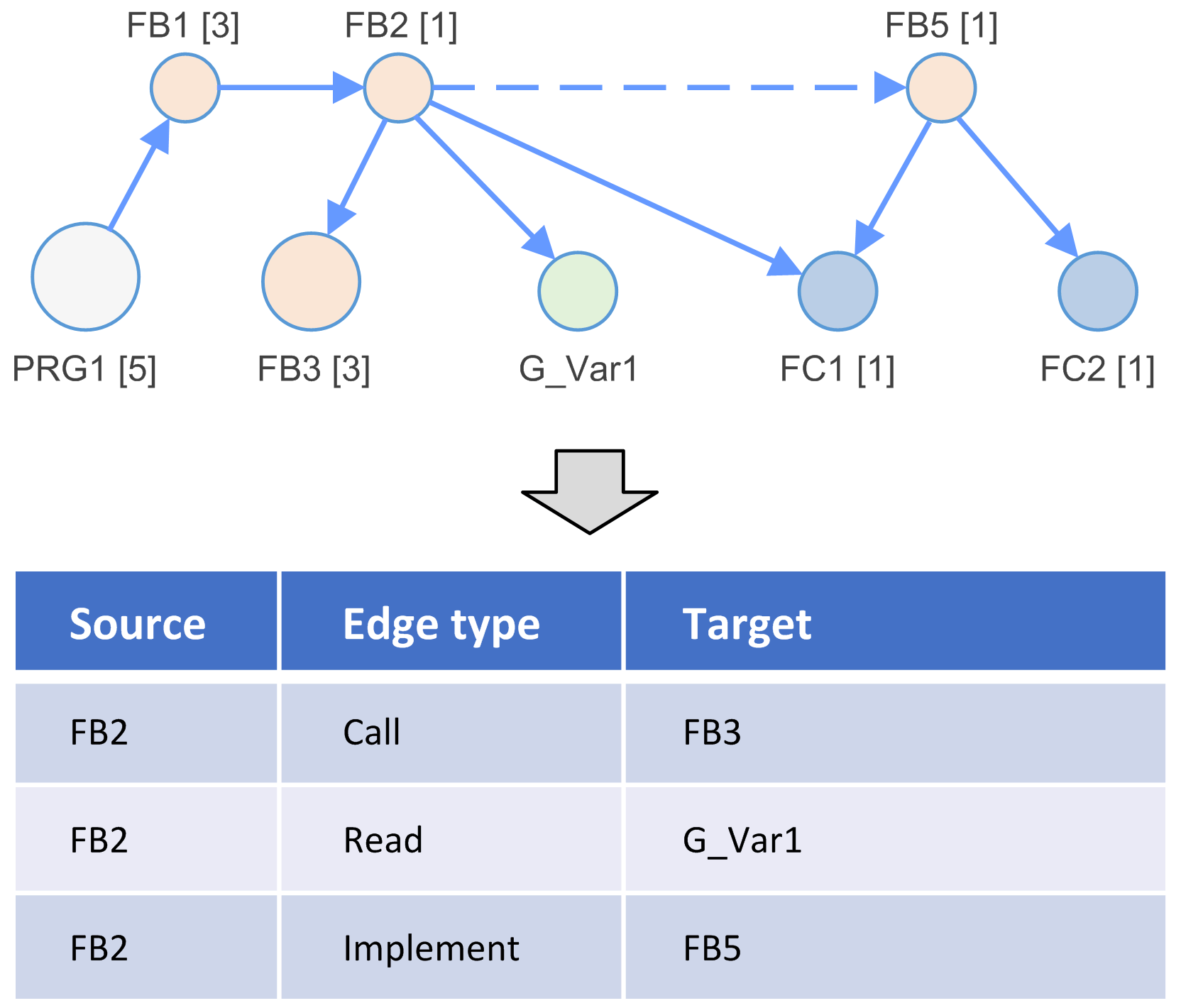
Beispiel für Knotentypen:
|
Knotentyp |
Beschreibung |
|---|---|
|
Funktionsbaustein |
Funktionsbaustein (FB) innerhalb des Abhängigkeitsmodells. Wird für jeden Funktionsbaustein erstellt, der im EcoStruxure Machine Expert-Projekt hinzugefügt wird. |
|
Programm |
Programm (PRG) innerhalb des Abhängigkeitsmodells. Wird für jedes Programm erstellt, das im EcoStruxure Machine Expert-Projekt hinzugefügt wird. |
|
Funktion |
Funktion (FC) innerhalb des Abhängigkeitsmodells Wird für jede Funktion erstellt, die im EcoStruxure Machine Expert-Projekt hinzugefügt wird. |
|
... |
... |
Beispiel für Kantentypen:
|
Kantentyp |
Beschreibung |
|---|---|
|
Lesen |
Lesevorgang mit dem Code als Quelle und einem Variablenknoten als Ziel. |
|
Schreiben |
Schreibvorgang mit dem Code als Quelle und einem Variablenknoten als Ziel. |
|
Aufruf |
Aufruf eines Funktionsbausteins, einer Methode, einer Aktion, eines Programms usw. mit dem Code als Quelle und einem Knoten als Ziel. |
|
Erweiterung |
Erweiterung eines Basistyps. Beispiel: FB-Erweiterung durch einen anderen Funktionsbaustein. |
|
... |
... |
Konzept der Analysestufen
Ein wichtiger Bestandteil der Codeanalyse ist der Quellcode-Analyzer, der das Sprachmodell in ein Abhängigkeitsmodell (die Analysedaten) umwandelt.
Der Quellcode-Analyzer basiert auf dem Konzept der so genannten Analysestufen. Diese Funktion wird verwendet, um Nutzbarkeit und Leistung zu optimieren (aus Speicher- und Prozessorsicht).
Beispiel:
-
Um die Erweiterungs- und Implementierungsabhängigkeiten zu identifizieren, kann eine schnelle Codeanalyse durchgeführt werden. Das nimmt weniger Zeit in Anspruch im Vergleich zu Aufruf-, Lese- oder Schreibabhängigkeiten.
-
Um eine Liste der Funktionsbausteine und der Erweiterungs- und Implementierungsabhängigkeiten zu erhalten, können Sie die Analyse bei einer bestimmten Analysetiefe stoppen.
-
Wenn detailliertere Informationen benötigt werden, muss die Analysetiefe für spezifische Elemente (z. B. zur Visualisierung einiger Funktionsbausteine in der Abhängigkeitsansicht) oder ggf. für die Objekte im Projekt (z. B. für Metrikergebnisse) erhöht werden.
Für den Anwender relevante Analysestufen:
Drei Ansätze sind von Bedeutung:
-
Minimale Analysetiefe (Phase 1+2): Der im Projekt und in den Navigatoren von EcoStruxure Machine Expert angezeigte Inhalt.
-
FBs, PRGs, FCs, DUTs usw.
-
Eigenschaften und die zugehörigen Get/Set-Methoden
-
Methoden
-
Aktionen
-
Strukturspezifische Informationen (Ordner usw.)
-
Bibliotheksreferenzen
Diese Analysetiefe nimmt am wenigsten Zeit in Anspruch.
-
-
Tiefe der Zwischenanalyse (Phase 3+4): Nächste Ebene der Informationen aus dem Quellcode.
Beispiel:
-
Variablen
-
Abhängigkeiten in Bezug auf das Lesen von Variablen
-
Abhängigkeiten in Bezug auf das Schreiben von Variablen
-
Aufruf von Methoden, Funktionen, Funktionsbausteine, Programmen usw.
Diese Analysetiefe benötigt mehr Zeit.
-
-
Maximale Analysetiefe (Stufe 5): Metrikinformationen auf der Grundlage der Implementierung (Quellcode).
Beispiel:
-
Halstead-Komplexität
-
Lines Of Code (LOC)
-
...
-
Diese Analysetiefe nimmt am meisten Zeit in Anspruch. (nur für Metriken oder Konventionen)
Semantische Webtechnologien
Die offene und flexible Codeanalyse-Funktion basiert auf semantischen Webtechnologien. Nachstehend einige dieser Technologien:
-
Resource Description Framework (RDF) - RDF-Modell
Siehe https://en.wikipedia.org/wiki/Resource_Description_Framework.
-
RDF-Datenbank (semantische Webdatenbank) - RDF Triple Storage
-
SPARQL-Protokoll und RDF-Abfragesprache - SPARQL
Synchronisation Abhängigkeitsmodell - RDF-Modell
Das Abhängigkeitsmodell ist das Ergebnis der Ausführung einer Codeanalyse.
Um eine Verbindung zu einer offenen, flexiblen Codeanalyse-Funktion mit Abfragesprachenunterstützung herzustellen, wird das Abhängigkeitsmodell mit einem RDF-Modell synchronisiert.
RDF Triple Storage
Zur Unterstützung der Analyse umfangreicher Projekte wird das RDF-Modell in einem separaten Prozess verwaltet, der als bezeichnet wird.
wird standardmäßig verwendet. Nach Bedarf kann das Verhalten im konfiguriert werden.
SPARQL und RDF
Das Resource Description Framework (RDF) ist ein Datenmodell zur Beschreibung von Ressourcen und der Beziehungen zwischen diesen Ressourcen.
Beispiel:
|
:(Subjekt) |
:(Prädikat) |
:(Objekt) |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
SPARQL ist ein Akronym für „Sparql Protocol and RDF Query Language“. Die SPARQL-Spezifikation (https://www.w3.org/TR/sparql11-overview/) stellt Sprachen und Protokolle für die Abfrage und Manipulation von RDF-Graphen bereit - vergleichbar mit SQL-Abfragen.
Beispiel für eine einfache SPARQL-Abfrage, um die Knoten-IDs und zugehörigen Namen der Funktionsbausteine eines RDF-Modells abzurufen:
SELECT ?NodeId ?Name
WHERE {
# Select all FunctionBlocks and their names
?NodeId a :FunctionBlock ;
:Name ?Name .
}