Concetto di Code Analysis
Panoramica
Questo capitolo fornisce una panoramica sui concetti di Code Analysis come integrati in EcoStruxure Machine Expert.
Componenti software di Code Analysis
Lo schema fornisce una panoramica dei componenti software di alto livello di Code Analysis:
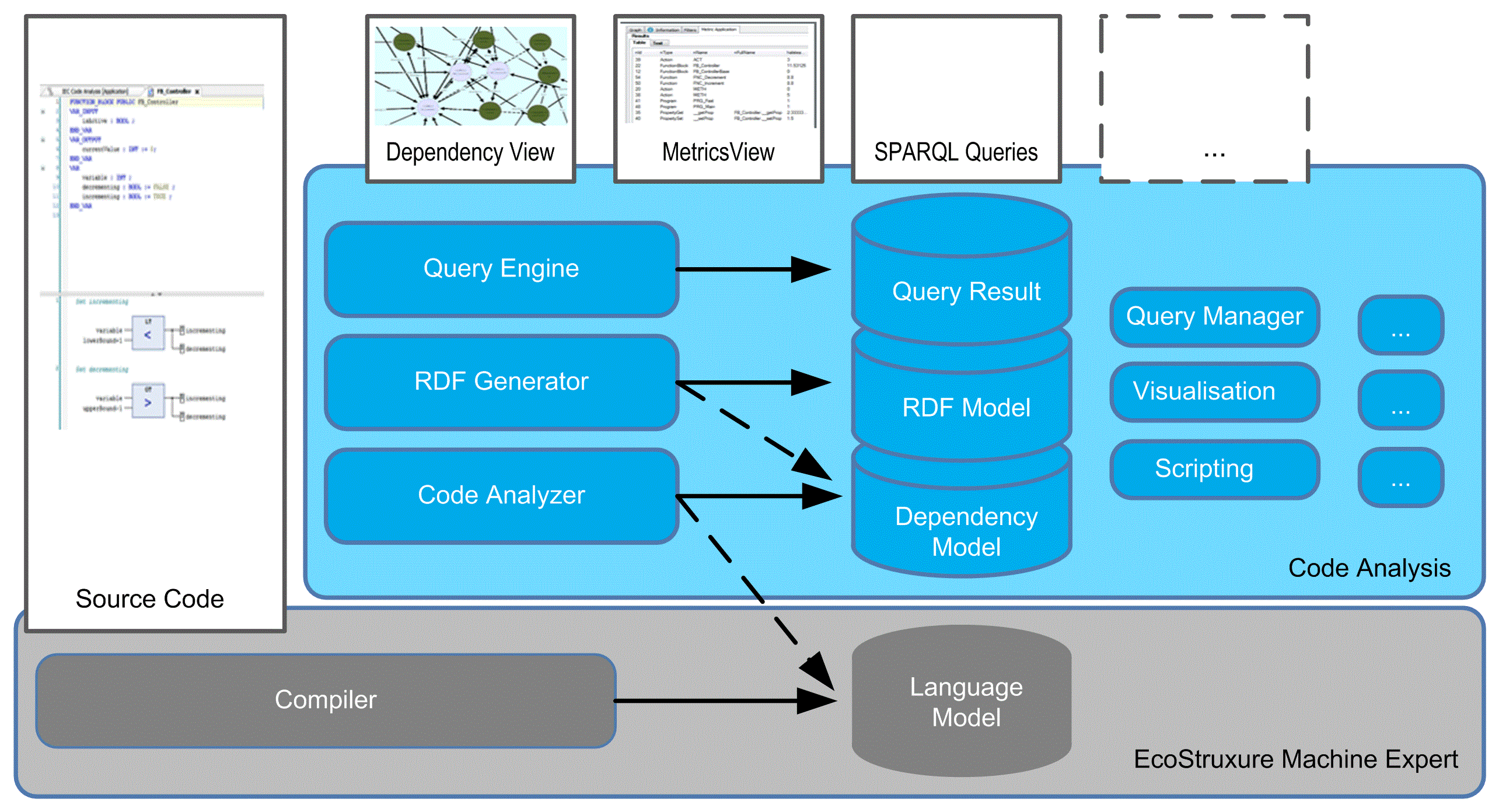
È possibile suddividere i componenti in tre tipi diversi:
-
Componenti UI che visualizzano dati:
-
Editor per scrivere il codice sorgente.
-
Editor per visualizzare i risultati come metriche o convenzioni, oppure una rappresentazione grafica della struttura del codice sorgente.
-
-
Modelli dati come ingressi o uscite di altri componenti:
-
Modello linguaggio
-
Modello dipendenza
-
Modello RDF (Resource Description Framework)
-
Risultati query
-
-
Componenti che trasformano i dati:
-
Il compilatore del codice sorgente (con il modello linguaggio come risultato) elabora il codice sorgente per controllare la sintassi e crea il modello di linguaggio per generare il codice eseguibile eseguito sui controller.
-
L'analizzatore del codice sorgente (con il modello dipendenza come risultato) analizza il modello di linguaggio e lo trasforma in un modello dipendenza (e lo tiene aggiornato).
-
Il generatore del modello RDF (con il modello RDF come risultato) trasforma il modello dipendenza in un modello RDF per creare il collegamento con le tecnologie Web semantiche.
-
Il motore di esecuzione Query (con i risultati della query come risultato) esegue le query SPARQL sul modello RDF per ottenere i risultati della query.
-
Concetto di dati di analisi (Modello dipendenza)
L'applicazione viene analizzata e generato un modello dipendenza.
Il modello dipendenza è un elenco di nodi collegati tramite edge.
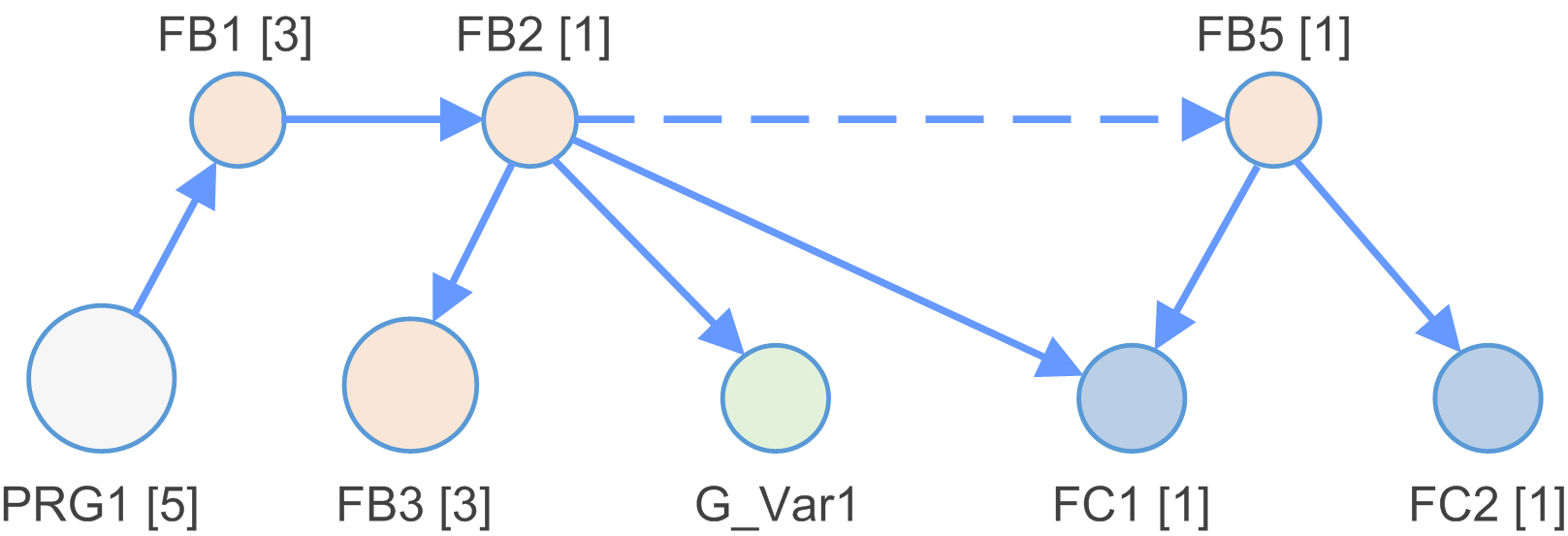
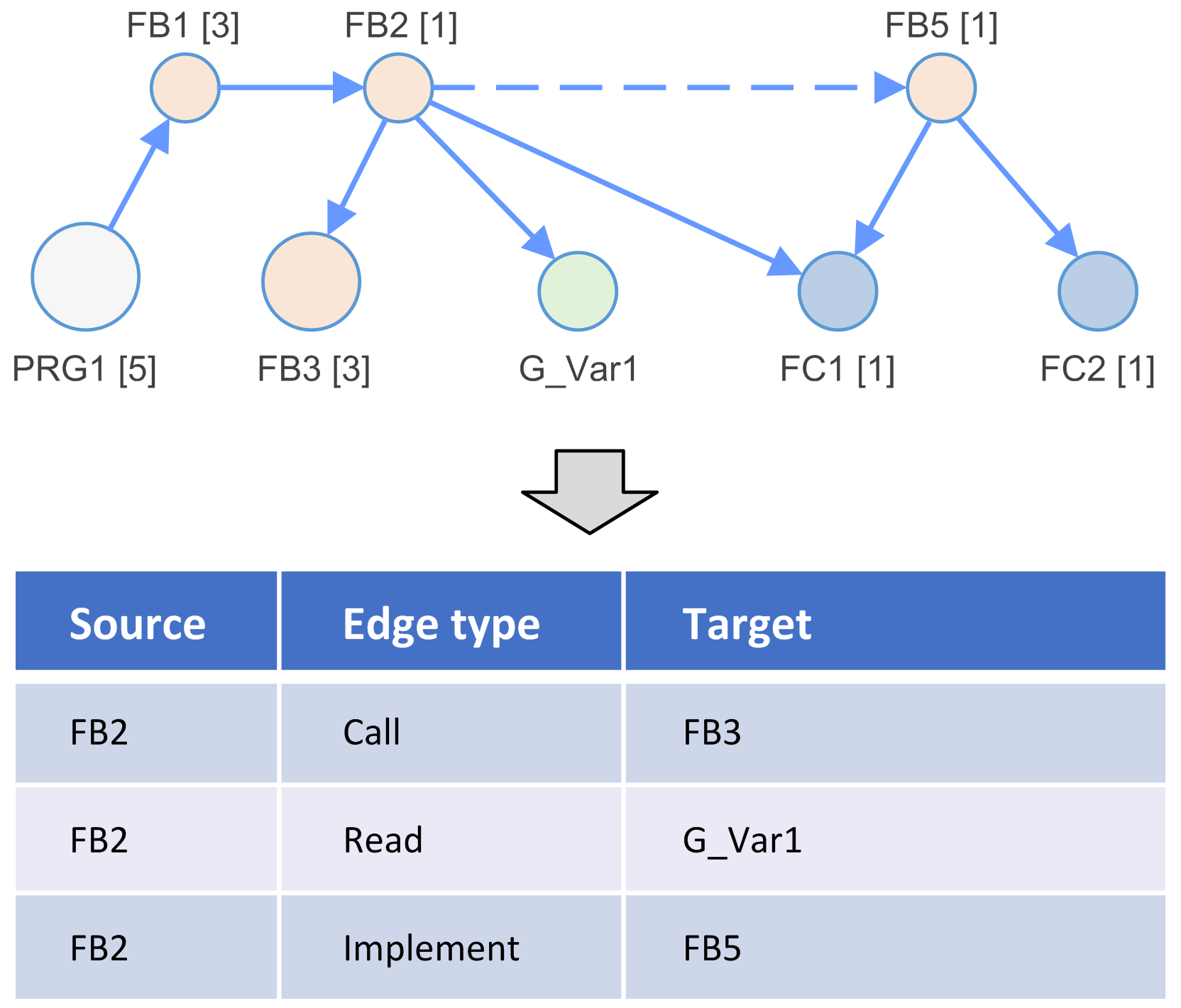
Esempi di tipi di nodi:
|
Tipo di nodo |
Descrizione |
|---|---|
|
Blocco funzione |
Blocco funzione (FB) all'interno del modello dipendenza. Creato per ogni blocco funzione aggiunto al progetto EcoStruxure Machine Expert. |
|
Programma |
Programma (PRG) all'interno del modello dipendenza. Creato per ogni programma aggiunto al progetto EcoStruxure Machine Expert. |
|
Funzione |
Funzione (FC) all'interno del modello dipendenza. Creata per ogni funzione aggiunta al progetto EcoStruxure Machine Expert. |
|
... |
... |
Esempi di tipi di edge:
|
Tipo edge |
Descrizione |
|---|---|
|
Lettura |
Operazione di lettura dal codice come sorgente in un nodo di variabile come destinazione. |
|
Scrittura |
Operazione di scrittura dal codice come sorgente in un nodo di variabile come destinazione. |
|
Chiamata |
Chiamata di un blocco funzione, metodo, azione, programma e così via, dal codice come sorgente a un nodo di destinazione. |
|
Estendi |
Estensione di un tipo di base. Ad esempio, estensione di FB da parte di un altro blocco funzione. |
|
... |
... |
Concetto delle fasi di analisi
Un componente importante dell'analisi del codice è l'analizzatore del codice sorgente, che trasforma il modello di linguaggio in un modello di dipendenza (i dati di analisi).
L'analizzatore del codice sorgente si basa su un concetto denominato fasi di analisi, Questa funzione consente di ottimizzare fruibilità e prestazioni (dal punto di vista della memoria e del processore).
Esempio:
-
Ottenere dipendenze di estensione e implementazione è un'operazione rapida di analisi del codice e richiede meno tempo rispetto alle dipendenze di chiamata, lettura e scrittura.
-
Per ottenere l'elenco di blocchi funzione e le dipendenze di estensione e implementazione, è possibile interrompere l'analisi a una profondità di analisi specifica.
-
Se sono richiesti più dettagli, occorre aumentare la profondità di analisi per elementi specifici (ad esempio, per visualizzare alcuni blocchi funzione nella vista dipendenza), oppure eventualmente per gli oggetti nel progetto (ad esempio per ottenere risultati delle metriche).
Fasi di analisi rilevanti per l'utente:
Vi sono tre approcci rilevanti:
-
Profondità minima di analisi (fase 1+2): Il contenuto visibile nel progetto e nei navigatori EcoStruxure Machine Expert.
-
FB, PRG, FC, DUT e così via
-
Proprietà e relativi metodi get/set
-
Metodi
-
Azioni
-
Informazioni strutturali (cartella e così via)
-
Riferimenti librerie
Questa profondità di analisi richiede meno tempo.
-
-
Profondità di analisi intermedia (fase 3+4): Livello successivo di informazioni dal codice sorgente.
Ad esempio:
-
Variabili
-
Lettura di dipendenze di variabile
-
Scrittura di dipendenze di variabile
-
Chiamata di metodi, funzioni, blocchi funzione, programmi e così via
Questa profondità di analisi richiede più tempo.
-
-
Profondità massima di analisi (fase 5): Informazioni sulle metriche basate sull'implementazione (codice sorgente).
Ad esempio:
-
Complessità Halstead
-
Linee di codice (LOC)
-
...
-
Questa profondità di analisi richiede il tempo maggiore. (Solo per metriche o convenzioni).
Tecnologie Web semantiche
La funzionalità aperta e flessibile di analisi del codice si basa su tecnologie Web semantiche. Alcune di queste tecnologie sono:
-
Resource Description Framework (RDF) - Modello RDF
Vedere https://en.wikipedia.org/wiki/Resource_Description_Framework.
-
Database RDF (Database Web semantico) - un Triple Storage RDF
-
SPARQL Protocol and RDF Query Language - SPARQL.
Modello dipendenza per sincronizzazione modello RDF
Il modello dipendenza è il risultato di un'esecuzione dell'analisi del codice.
Per il collegamento a una funzionalità di analisi del codice aperta e flessibile con il supporto del linguaggio query, il modello è sincronizzato con un modello RDF.
Triple Storage RDF
Per il supporto dell'analisi di grandi progetti, il modello RDF viene tenuto in un processo separato denominato .
Per impostazione predefinita, si utilizza . Se richiesto, è possibile configurare il comportamento nel .
SPARQL e RDF
Resource Description Framework (RDF) è un modello dati per la descrizione delle risorse e delle loro relazioni reciproche.
Esempio:
|
:(Oggetto) |
:(Predicato) |
:(Oggetto) |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
SPARQL è l'acronimo di Sparql Protocol and RDF Query Language. La specifica SPARQL (https://www.w3.org/TR/sparql11-overview/) fornisce linguaggi e protocolli a query e manipola le immagini RDF - analogamente alle query SQL.
Esempio di una semplice query SPARQL per ottenere gli ID del nodo e relativi nomi dei blocchi funzione di un modello RDF:
SELECT ?NodeId ?Name
WHERE {
# Select all FunctionBlocks and their names
?NodeId a :FunctionBlock ;
:Name ?Name .
}