Database maintenance
PME uses databases to store information such as system configuration, data logs, and system event log messages. These databases must be maintained to preserve performance, manage disk space usage, and guard against data loss in case of database failure. Maintenance is the key to a healthy system that supports system longevity and future scalability. You must not ignore maintenance. Non-maintenance may lead to system downtime and you might need to rebuild the system from scratch.
notice
LOSS of data
| ● | Back up the database at regular intervals. |
| ● | Back up the database before upgrading or migrating the system. |
| ● | Back up the database before trimming it. |
| ● | Back up the database before making manual database edits. |
| ● | Verify correct database behavior after making database or system changes. |
Failure to follow these instructions can result in permanent loss of data.
Database maintenance for PME includes the following key activities:
- Performance maintenance
- Accurate and up-to-date query statistics
- Minimize index fragmentation
- Data archive and trim
- Database integrity check
Based on the key activities, see Consolidated recommendation for database maintenance.
Performance maintenance
For performance maintenance, enable and schedule the following daily maintenance tasks for all PME systems of any configuration:
| Database | Type of Data | Maintenance Tasks* | ||
|---|---|---|---|---|
| Maintenance (update statistics and index defragmentation) | Trim** | Size Notification | ||
| ApplicationModules | Web Applications related configuration data and system event log entries. | ✓ | ✓ | – |
| ION_Data | Historical power system data such as interval data logs, waveforms and alarms. | ✓ | ✓ | ✓
NOTE: For systems with SQL Server Express, enable SQL Express Database Size Notification. |
| ION_Network | Device network and other system configuration data. | ✓ | – | – |
| ION_SystemLog | Non-Web Applications related system event log entries. | ✓ | ✓ | – |
* See Default maintenance task settings for basic task definitions.
** Keep the last 30 days of data.
In Standalone PME systems, the database maintenance tasks are pre-configured and scheduled to run automatically by default. For Distributed Database PME systems, you need to configure the tasks and set up the schedules manually.
For more information, see the Database maintenance section in the Configuring chapter of this guide.
Accurate and up-to-date query statistics
SQL Server uses statistics to create query plans that improve query performance. As the database increases and holds more data, the statistics becomes less relevant over the time. Updating statistics ensures that queries run with relevant statistics.
For all systems, it is recommend to update database statistics daily. The following table shows the default database maintenance task schedules for standalone systems:
| Database | Task* | Trigger Time |
|---|---|---|
| ApplicationModules | Maintenance | Daily at 03:30 |
| ION_Data | Maintenance | Daily at 02:00 |
| ION_Network | Maintenance | Daily at 07:30 |
| ION_SystemLog | Maintenance | Daily at 07:05 |
* See Default maintenance task settings for basic task definitions.
In distributed systems, the database maintenance tasks are not pre-configured. You need to set up these tasks manually.
These scheduled tasks trigger the DatabaseMaintenance.ps1 Windows PowerShell script. This script executes the local [Maintenance].[UpdateStatisticsAll] stored procedure in each database.
Check the PME system logs and SQL Server logs to confirm that the scheduled tasks are completed successfully. The log might report errors if an issue arises. As the database grows, these jobs will take longer time to complete.
See Microsoft’s SQL Server documentation on SQL Server Query Statistics for more information about query statistics.
For more information, see the Database maintenance section in the Configuring chapter of this guide.
Minimize index fragmentation
Database index maintenance is important to ensure optimal performance. When data is written to the databases, fragmentation occurs. Heavy fragmented indexes can degrade query performance and reduce PME’s response time.
To minimize index fragmentation, monitor the fragmentation regularly and perform re-indexing.
For small to medium size systems:
It is recommend to re-index daily. The following table shows the default database maintenance task schedules for standalone systems:
| Database | Task* | Trigger Time |
|---|---|---|
| ApplicationModules | Maintenance | Daily at 03:30 |
| ION_Data | Maintenance | Daily at 02:00 |
| ION_Network | Maintenance | Daily at 07:30 |
| ION_SystemLog | Maintenance | Daily at 07:05 |
* See Default maintenance task settings for basic task definitions.
In distributed systems, the database maintenance tasks are not pre-configured. You need to set up these tasks manually.
These scheduled tasks trigger the DatabaseMaintenance.ps1 Windows PowerShell script. This script executes the local [Maintenance].[ DefragIndexAll] stored procedure in each database.
Check the PME system logs and SQL Server logs to confirm that the scheduled tasks are completed successfully. The log might report errors if an issue arises. As the database grows, these jobs will take longer to complete.
For large systems:
For large systems with ION_Data growing over 100 GB in size, it is important to review the frequency of the [ION_Data] database maintenance scheduled task and switch to running them manually.
Index fragmentation in ION_Data is unavoidable for large systems because of the amount of data written to the system and queried on a regular basis. Index fragmentation is also common when database reads exceeds database writes, that is, when PME is configured with added components to move data from PME to another non-PME system.
For large systems, you need to monitor the index fragmentation daily. To monitor, run the following SQL commands against the database:
Both the commands generate a report on index fragmentation. The time it takes to complete these statements depend on the amount of data in the table and the level of fragmentation. The more fragmented the index, the longer the query will run. You should expect the query to return results within 1 to 20 minutes.
DBCC SHOWCONTIG
DBCC SHOWCONTIG displays fragmentation information for the data and indexes for specified tables.
NOTE: This command applies to SQL Server 2008 to 2019 and is expected to be deprecated in a future version of SQL Server.
For ION_Data, run the following commands:
Review the output from DBCC SHOWCONTIG for the following three statistics:
1. Average Page Density:
Shows the accurate indication of how full your pages are. A high percentage means the pages are almost full, and a low percentage indicates much free space. This value should be compared to the fill factor setting specified when the index was created to decide whether or not the index is internally fragmented. The fill factor is the percentage of space on each leaf-level page that should be filled with data, and it is applied only when the index is created, rebuilt or reorganized. If the Average Page Density and Fill Factor are close in value, then it would suggest that there is little index fragmentation.
2. Scan Density:
Shows the ratio between the Best Count of extents that should be necessary to read when scanning all the pages of the index, and the Actual Count of extents that was read. This percentage should be as close to 100% as possible. Defining an acceptable level is difficult, but anything under 75% definitely indicates external fragmentation.
3. Logical Scan Fragmentation:
Shows the ratio of pages that are out of logical order. The value should be as close to 0% as possible and anything over 10% indicates external fragmentation.
See DBCC SHOWCONTIG (Transact-SQL) for more information on DBCC SHOWCONTIG command.
sys.dm_db_index_physical_stats
sys.dm_db_index_physical_stats also returns size and fragmentation information for the data and indexes of the specified table or view in SQL Server. This command is available in SQL Server 2005 or later.
For ION_Data, run the following commands to show fragmentation details for tables with more than 100,000 rows and a fragmentation level of greater than 50%. Comment out the WHERE clause to show results for all table indices. The output is sorted by fragmentation level from highest to lowest.
USE ION_Data
GO
SELECT
DB_NAME(db_id()) AS DatabaseName,
OBJECT_NAME(object_id) AS TableName,
object_id,
index_id,
index_type_desc,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM
sys.dm_db_index_physical_stats(db_id(),DEFAULT, DEFAULT, DEFAULT, 'SAMPLED')
WHERE
(record_count > 100000) AND (avg_fragmentation_in_percent > 50)
ORDER BY
avg_fragmentation_in_percent DESC;When reviewing the output from sys.dm_db_index_physical_stats, review the values in the avg_fragmentation_in_percent column. You should defragement the indexes, if the fragementation is 10% and above.
See sys.dm_db_index_physical_stats (Transact-SQL) for more information on sys.dm_db_index_physical_stats command.
Correcting index fragmentation
Any index with over 10% fragmentation should be corrected.
There are different corrective statements depending on the level of fragmentation. For PME, select the statements as follows:
| Fragmentation Percentage | Corrective Statement | Remarks |
|---|---|---|
| 10 to 30% | ALTER INDEX REORGANIZE | Reorganizing an index uses minimal system resources and is an online operation, which means PME can remain online during this operation. |
| > 30% | ALTER INDEX REBUILD WITH (ONLINE = OFF) | Rebuilding an index drops and re-creates the index. Depending on the type of index and Database Engine version, a rebuild operation can be done online or offline. For large indexes, it is recommended to perform this operation offline. |
See Resolve index fragmentation by reorganizing or rebuilding indexes for more information on correcting index fragmentation.
Data archive and trim
The archive strategy supports data retention and compliance, while the trim strategy supports disaster recovery goals.
Archive and Trim shortens the backup process by keeping only business critical data in the live database and also reduces the resource demands in the disaster recovery efforts by shrinking the database to backup and restore.
Archiving is not recommended since it fractures the data into multiple databases. PME is unable to query multiple databases at the same time to make comparisons in the data. It is possible to run reports against an archived database, but it can only be done on one database at a time.
However, the ION_Data database may need to be reduced in size for two reasons:
- SQL Server Express is used as the database engine, which has a limit of 10 GB for the .mdf file.
- SQL Server (Standard or Enterprise edition) is used as the database engine and the ION_Data database has become so large that query performance (in Vista for example) is not acceptable to the PME system users. It is also important to ensure that the ION_Data database is trimmed well within the hard drive size, as it can affect the operation of PME.
For PME systems with considerable database growth (medium to very large systems), it is important to consider frequent removal of older and lesser used data from ION_Data. PME includes an ION_Data data archive maintenance task by default. The database archive task is pre-configured and disabled for standalone systems, while it must be manually added for distributed systems.
To determine if data archiving is needed, you must:
- Understand the importance of archive and trim
- Determine the data retention needs
- Develop the archive and trim strategy
Understand the importance of archive and trim
The purpose of the archive is to remove data from the live ION_Data database to reduce its overall size. An archive is a copy of a subset of data from the live ION_Data database based on a date range and the type of data (Data Records, Waveforms and Events).
When an ION_Data archive is created, it is attached to the SQL Server database engine so that its data is still accessible to Vista and Diagrams. However, the data is not available to other applications in the Web Applications component.
NOTE: Data archival in PME is different from the normal terminology of archiving. PME's archive task does not remove data from the database, it only copies data to the archive. Once the data is archived in PME, it cannot be re-imported back.
We recommend to manually trim the database of historical data after each archive task.
Determine the data retention needs
The live system only needs to hold as much data as needed for business. Consider the following questions along with the business use cases to determine the data retention needs:
- What is the oldest date of data that is needed for trends and alarms?
- Is it sufficient to review older data trends only through web reports or diagrams?
- What date range of data is needed for historical reporting – start and end dates?
- How often should data be archived?
Develop the archive and trim strategy
These questions determine key aspects of the archive and trim strategy, in particular:
- When to archive data from the live database?
- When to trim data from the live database?
- When to delete historical archives?
Example: Archive and Trim Strategy
The following diagram illustrates an example ION_Data archive and trim strategy for a small to medium system that started data collection in Q4 2016 and the strategy planned till 2021.
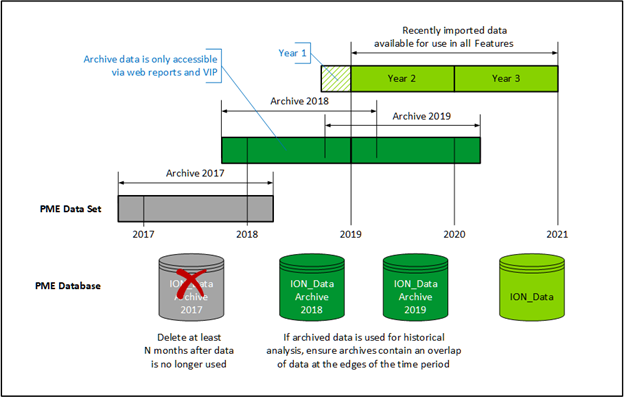
Based on the business needs, the data retention requirements are:
- Perform analysis with at least two calendar years of data in the main PME system
- Reporting on the last 3 calendar years of data
- Data older than 3 calendar years can be deleted
The example strategy is as follows:
- Keep two calendar years of data in the main ION_Data database.
-
Start archive activity at the end of Q1 of the third year.
NOTE: There should be 2 years and 3 months of data in ION_Data.
In this example, archive data from start of Q4 Year 1 to end of Q1 Year 3 into the database called ION_Data Archive Year 1. This results in a new archive database named ION_Data_Archive_2017 containing data from 01 September 2016 to 01 April 2018.
- Backup the newly created archive database.
-
Schedule the archive activity once per year starting at the end of Q1 of the current year.
NOTE: Archive the older year of data with an additional 3 months on each side of the year of interest.
- After each successful archive, backup the newly created archive database.
- Schedule the trim activity to trim data in the last 3 months of the dataset from the main ION_Data database.
- Schedule the trim to run every 3 months.
- When an archive database contains data older than 3 years, mark the archive database for deletion.
- Delete the marked archive database after 12 months of non-use.
NOTE: This strategy creates an overlap of data for every year.
Recommendation for archive and trim
- Archive and trim the ION_Data database often and in small batches. Together these two tasks reduce the size of ION_Data and its backup files.
- Archive historical data often even when disk space is not an issue or when not using SQL express.
- Trim historical data in small batches and often.
- Always perform a database trim after verifying a new archive.
Recommended consolidated archive and trim plan for systems
The recommended consolidated archive plan of ION_Data database for the different purpose of PME system are as follows:
| Archive strategy parameter | Purpose of PME system | ||
|---|---|---|---|
| Analysis & decision making |
Real-time monitoring & troubleshooting |
Critical large advanced distributed system |
|
| Maximum data retention (ION_Data and Archive databases) | 4 years | 1 year | 4 years |
| Live data in ION_Data | 3 years | 1 year | 2 years |
| ION_Data archives | Start after end of year 3 | Not applicable | Start after end of year 2 |
| Archive frequency | Annually | Not applicable | Every 3 months |
| Number of archives to store on server | 1 | Not applicable | 8 |
| Additional IT resources needed for archive databases* | Use database growth calculator to estimate size archive database | Not applicable | Use database growth calculator to estimate size archive database |
The recommended consolidated trim plan of ION_Data database for the different purpose of PME system are as follows:
| Trim strategy parameter | Purpose of PME system | ||
|---|---|---|---|
| Analysis & decision making |
Real-time monitoring & troubleshooting |
Critical large advanced distributed system |
|
| Trim | Data with timestamps older than 3 years from today | Data with timestamps older than 1 year from today | Data with timestamps older than 2 years from today |
| Trim frequency | Monthly | Monthly | Monthly |
Database integrity check
Database corruption is a rare event that is usually caused by inoperative hardware on the server. A database integrity check reviews the allocation and structural integrity of all objects in each database to ensure it is not corrupt.
Run DBCC CHECKDB in SQL Server Management Studio on all PME related databases once per month or quarter.
Check for errors reported in the output of DBCC CHECKDB. A database with integrity displays the following at the end of the output.
CHECKDB found 0 allocation errors and 0 consistency errors in database 'ION_Data'.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
See DBCC CHECKDB (Transact-SQL) for more information on database integrity.
Consolidated recommendation for database maintenance
Based on the key activities discussed, the following is the consolidated recommendation for database maintenance as per the systems:
For all systems (Small, Medium, and Large):
- Schedule the ApplicationModules database trim task to run daily.
- Schedule the ION_SystemLog database trim task to run daily.
- If the number of connected devices have increased over time, review hardware and hard drive space requirements at least once per year to ensure server specifications meets growing demand.
- Review the frequency of the ION_Data database maintenance task as the system grows. Reduce the frequency from daily to weekly to monthly as the database grows and the maintenance tasks (Update statistics and re-indexing) take longer to complete.
- Never shrink the database container; it causes fragmentation.
- Archive and trim the ION_Data database regularly and in batches, such as 3 to 12 month data sets. Refer to Historical Data Archive and Trim Strategy for more information.
- Commission PME’s default ION_Data archive Windows scheduled task.
- Develop a process and schedule for:
- Verifying the newly created archive database
- Backing up the newly created archive database
- Deleting the archive database when necessary
For large ION_Data databases (> 100 GB):
Large ION_Data databases require additional effort to maintain because all the maintenance task might not run completely.
- Disable the ION_Data database maintenance task
- With large systems, index fragmentation occurs quickly and is unavoidable.
- Defragmentation takes lot of time and the performance gained because of defragmentation is comparatively less.
- If you plan to rebuild indexes, ensure that you have an equivalent amount of free space as the database size.
- If ION_Data database increases over 100 GB unexpectedly, it can be due to following reasons:
- Database fragmentation can occur when there are more database read than database write actions.
- Power quality and / or waveform logging is enabled accidentally, then power quality data increases.
- More data points are logged than usual and frequent logging is performed.
- Defragmenting indexes may require a lot of free hard drive space to allow reindexing to succeed. Review hard drive space requirements.